고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
기본 미션
교차 검증을 그림으로 설명하기 Ch.05(05-3)

K-Fold 교차 검증 과정
- 전체 데이터셋을 Training Set과 Test Set으로 나눈다.
- Training Set를 Traing Set + Validation Set으로 사용하기 위해 k개의 폴드로 나눈다.
- 첫 번째 폴드를 Validation Set으로 사용하고 나머지 폴드들을 Training Set으로 사용한다.
- 모델을 Training한 뒤, 첫 번 째 Validation Set으로 평가한다.
- 차례대로 다음 폴드를 Validation Set으로 사용하며 3번을 반복한다.
- 총 k 개의 성능 결과가 나오며, 이 k개의 평균을 해당 학습 모델의 성능이라고 한다.
선택미션
앙상블 모델 손코딩 코랩 화면 인증샷
앙상블 학습
더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘입니다.
랜덤 포레스트
대표적인 결정 트리 기반의 앙상블 학습 방법입니다. 부트스트랩 샘플을 사용하고 랜덤하게 일부 특성을 선택하여 트리를 만드는 것이 특징입니다.
# 와인 데이터셋을 판다스로 불러오고 훈련 세트와 테스트로 분리
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('http://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))출력된 결과를 보면 훈련세트에 다소 과대 적합된 결과를 확인 할 수 있다.

rf.fit(train_input, train_target)
print(rf.feature_importances_)
RandomForestClassfier에는 자체적으로 모델을 평가하는 점수를 얻을 수 있다. 랜덤 포레스트는 훈련 세트와 중복을 허용하여 부트스트랩 샘플을 만들어 결정 트리를 훈련합니다. 이때 부트스트랩 샘플에 포함되지 않고 남는 샘플을 OOB(Out Of Bag)샘플이라고 하며 이 남는 샘플로 훈련한 결정 트리를 평가할 수 있습니다.
RandomForestClassfier 클래스의 oob_score 매개변수를 True로 지정하면 랜덤 포레스트는 각 결정 트리의 OOB 점수를 평균하여 출력합니다.
rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_)
엑스트라 트리
랜덤 포레스트와 비슷하게 결정 트리를 사용하여 앙상블 모델을 만들지만 부트스트랩 샘플을 사용하지 않습니다. 대신 랜덤하게 노드를 분할해 과대적합을 감소시킵니다.
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))


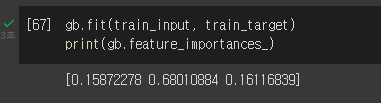
그레디언트 부스팅
랜덤 포레스트나 엑스트라 트리와 달리 결정 트리를 연속적으로 추가하여 손실 함수를 최소화하는 앙상블 방법입니다. 이런 이유로 훈련 속도가 조금 느리지만 더 좋은 성능을 기대할 수 있습니다.

히스토그램 기반 그레이팅 부스팅
그레이디언트 부스팅의 속도를 개선한 것이며 안정적인 결과와 높은 성능으로 매우 인기가 높습니다.

XGBoost
XGBoost는 Extreme Gradient Boosting의 약자이다. Boosting 기법을 이용하여 구현한 알고리즘은 Gradient Boost 가 대표적인데 이 알고리즘을 병렬 학습이 지원되도록 구현한 라이브러리가 XGBoost 이다. Regression, Classification 문제를 모두 지원하며, 성능과 자원 효율이 좋아서, 인기 있게 사용되는 알고리즘이다.

lightGBM
LightGBM은 XGBoost와 함께 부스팅 계열 알고리즘에 각광받는 모델입니다. XGBoost의 경우도 물론 GBM 보다 학습속도가 빠르지만 GridSearchCH로 하이퍼 파라미터를 튜닝하기에는 매우 많은 시간이 걸린다는 단점이 존재합니다. LightGBM은 XGBoost와 비교해 큰 예측 성능 차이를 보이지 않으면서 학습 시간을 상당히 단축시킨 모델입니다. LightGBM은 이러한 장점을 가지고 있지만 공식 문서에 따르면 일반적으로 10,000 건 이하의 데이터 세트를 다루는 경우 과적합 문제가 발생하기 쉽다는 단점이 있습니다.

후우.. 퇴근하고 따라가기 바쁨
기간내에는 업무일정으로 다는 못할 거같으니
그래도 마지막까지 고고싱

Reference
https://wooono.tistory.com/105
[ML] 교차검증 (CV, Cross Validation) 이란?
교차 검증이란? 보통은 train set 으로 모델을 훈련, test set으로 모델을 검증한다. 여기에는 한 가지 약점이 존재한다. 고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면, 결
wooono.tistory.com
K Fold Cross Validation
K Fold Cross Validation 조대협 (http://bcho.tistory.com) K 폴드 크로스 벨리데이션 / 교차 검증이라고도 함. 용어 정리. 별거 있는건 아니고 전체 데이타를 K개로 나눈다음. (각각을 폴드라고함), 첫번째 학
bcho.tistory.com
https://kimdingko-world.tistory.com/184
[머신러닝 완벽가이드] LightGBM
LightGBM¶ LightGBM은 XGBoost와 함께 부스팅 계열 알고리즘에 각광받는 모델입니다. XGBoost의 경우도 물론 GBM 보다 학습속도가 빠르지만 GridSearchCH로 하이퍼 파라미터를 튜닝하기에는 매우 많은 시간이
kimdingko-world.tistory.com
XGBoost 개념 이해
XGBoost 알고리즘의 개념 이해 조대협 (http://bcho.tistory.com) XGBoost는 Gradient Boosting 알고리즘을 분산환경에서도 실행할 수 있도록 구현해놓은 라이브러리이다. Regression, Classification 문제를 모두..
bcho.tistory.com
728x90
반응형
'Developer > 혼공단' 카테고리의 다른 글
| 혼공단 머신러닝+딥러닝 6주차 미션 - Chapter 07 (0) | 2022.03.04 |
|---|---|
| 혼공단 머신러닝+딥러닝 5주차 미션 - Chapter 06 (0) | 2022.03.04 |
| 혼공단 머신러닝+딥러닝 3주차 미션 - Chapter 04 (0) | 2022.02.22 |
| 혼공단 머신러닝+딥러닝 2주차 미션 - Chapter 03 (0) | 2022.02.22 |
| 혼공단 자바스크립트 6주차 미션 - Chapter 07 ~ 08 (0) | 2022.02.22 |





댓글 영역