고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형

<머신러닝 파워드 애플리케이션>은 에마누엘 아메장 Emmanuel Ameisen이 쓴 아마존 베스트셀러 <Building Machine Learning Powered Applications>의 번역서입니다.
이 책은 머신러닝 애플리케이션을 만드는 전 과정을 다루고 있습니다. 대부분의 책들이 머신러닝 알고리즘과 구현에 초점을 맞추는 반면에 이 책은 머신러닝 제품을 만들기 위한 아이디어, 기획, 측정 지표 선택, 데이터셋 선택, 알고리즘 구현과 디버깅, 배포, 모니터링에 이르기까지 실전에 필요한 지침과 유의사항이 가득 포함되어 있습니다. 업계의 유명한 데이터 과학자들과의 인터뷰도 실려 있어서 머신러닝 애플리케이션 어떻게 만들어야 하는지 더욱 실감 나게 배울 수 있습니다!

필자는 현재 딥러닝을 활용한 모델을 만들고 있다. 일전에 프로토타입 모델을 만들었는데 책에 내용이랑 비슷하게 시작해서 접근법이 틀리 않았다는 것을 알게 되었다. 처음부터 완벽한 모델을 만드는 것이아니라 적은 데이터로 학습을 하고 추론 결과를 통해서 데이터 증강 및 특징을 추가하는 식으로 시작하였다. 아래는 책 내용에 일부이다.
좋은 모델을 만드는 법
최초의 모델은 가장 간단한 모델로 시작할 수 있다. 문제에 대한 지식과데이터 기반으로 좋은 경험 법칙을 사용한다. 어떤 분야에 대해서 머신러닝을 적용하려면 해당 분야에 전문가로부터 배우면 시간을 많이 절약할 수 있다. 예를 들어 공장 설비 유지 보수 예측 시스템을 만들려면 먼저 공장 관리자를 만나 합리적으로 내릴 수 있는 것이 어떤 것인지 이해해야 한다.
1) 얼마자 자주 유지 보수 작업 수행하는지?
2) 일반적으로 유지 보수가 필요한 기계인지를 구분하는 장상은 무엇인지?
3) 유지 보수와 관련된 법률적인 조건은 무엇이 있는지?
만약 비슷한 문제를 푼 사람들이 있다면 비슷한 모델이나 데이터셋으로 만든 공개된 모델을 찾아보자.
-> 오픈 소스 코드와 데이터셋을 사용하기로 계획했다면 사용 권한을 확인하는 것이 좋다. 데이터 셋의 사용 범위와 라이센스를 확인한다.
머신러닝을 시작할때 초기부터 완벽한 모델을 만드는 것은 어렵다. 기존의 유사한 모델을 기반으로 프로토타입 모델을 선택한다. 대부분의 머신러닝 문제에서 데이터가 많으면 더 좋은 모델을 만들 수 있다. 하지만 이것이 가능한 가장 큰 데이터셋으로 시작해야 한다는 의미는 아니다.
프로젝트를 시작할 때 데이터셋이 작으면 분석하고 이해하기가 쉽다. 또 더 나은 모델을 만드는 방법을 이해할 수 있다. 쉽게 시작할 수 있는 초기 데이터셋을 얻는 것이 목표가 되어야 한다. 전략이 세워진 후에 큰 데이터 셋으로 사이즈를 늘리는 것이 합리적이다.
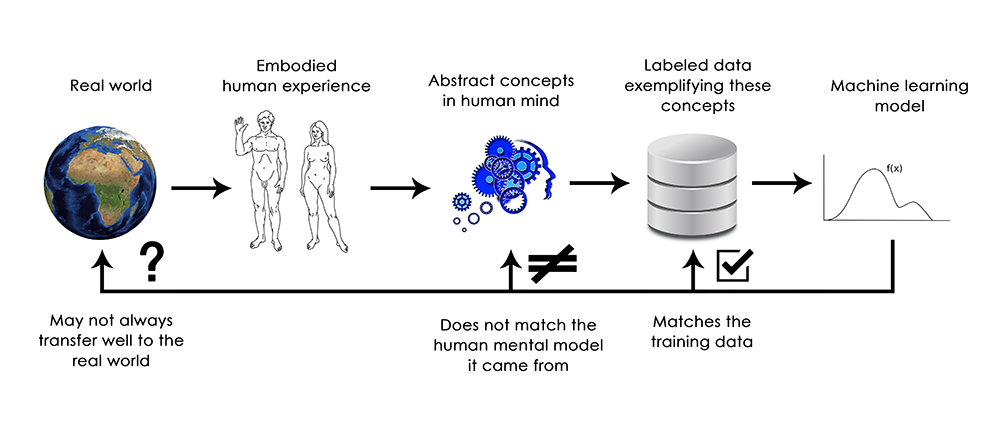
머신러닝 애플리케이션은 일반적인 애플리케이션보다 모니터링을 더욱 활용하여 관찰해야 한다. 비즈니스 관점으로 바라볼 때 사용자 니즈 및 상황이 달라지기 때문에 지속적으로 데이터의 특징을 찾아 모니터링 하여 모델을 개선할 수 있어야 한다.
<본 포스팅은 필자의 개인적인 생각입니다.>
머신러닝 파워드 애플리케이션:아이디어에서부터 완성된 제품까지
COUPANG
www.coupang.com
728x90
반응형
'Developer > IT 도서' 카테고리의 다른 글
| 다이내믹 프로그래밍 완전정복:빠르고 우아한 상향식 문제 풀이법 (0) | 2021.09.18 |
|---|---|
| 알고리즘 트레이닝 - 프로그래밍 대회 입문 가이드 (0) | 2021.09.18 |
| 실무 예제로 배우는 데이터 공학 (0) | 2021.08.04 |
| 인공지능 70 (재미있게 알아보는 AI 키워드) (0) | 2021.07.19 |
| Do it! Vue.js 입문 (0) | 2021.06.17 |





댓글 영역