고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형

Jupyter notebook은 대화형 파이썬 인터프리터(Interpreter)로서 웹 브라우저 환경에서 파이썬 코드를 작성 및 실행할 수 있는 툴이다. Visual Studio Code는 설치되어 있다고 가정하고 설치 과정을 포스팅하겠습니다.
Visual Studio Code 확장 탭을 클릭하고 Jupter를 검색하여 설치합니다.
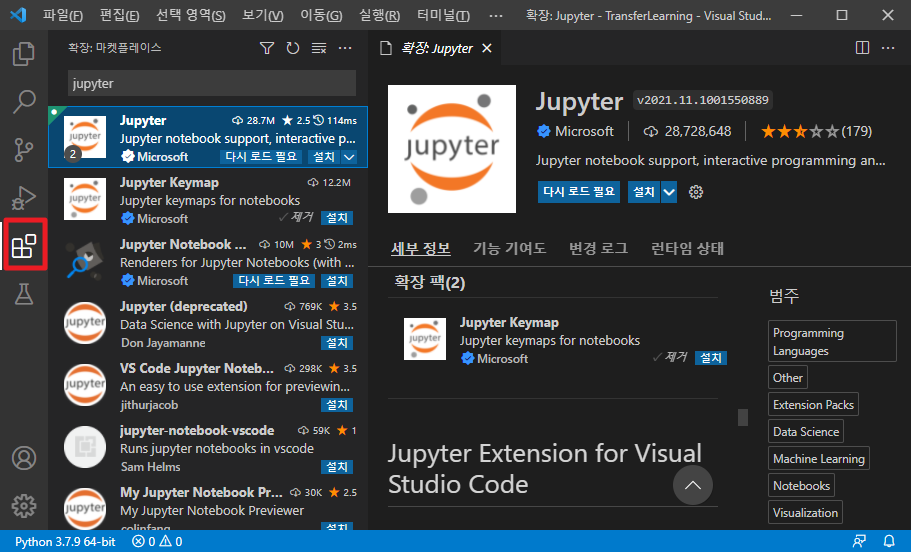
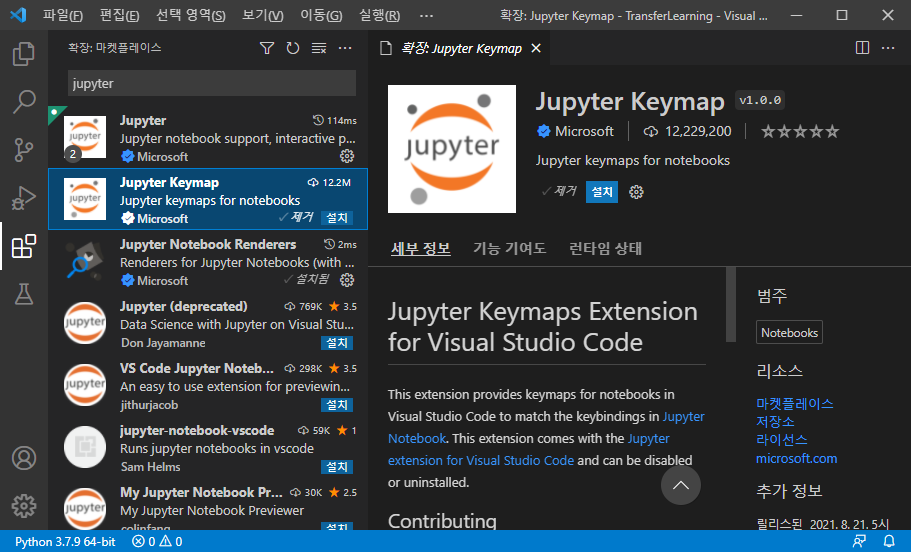
추가적으로 Jupyter Keymap 도 설치합니다. Jupyter Keymap은 jupyter notebook의 a, b, x, shift+enter, ctrl+enter 등 단축키를 Visual Studio Code에서 사용할 수 있는 확장 플러그인입니다.
python 파일의 경우 [파일 - 새면서]로 파일을 추가할 수 있지만 주피터 노트북 파일은 명령 팔레트로 만들어야 합니다.
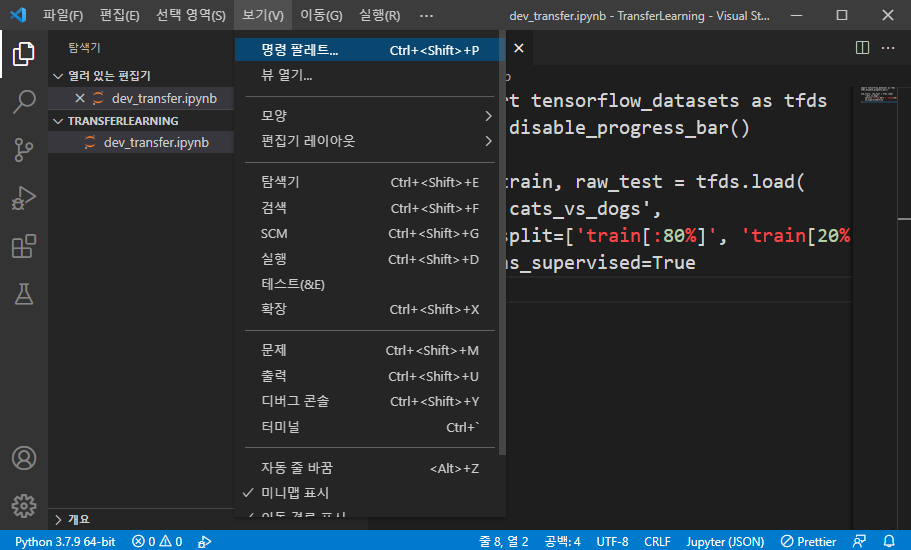
[보기 - 명령 팔레트]를 클릭하고 입력창에 Jupyter라고 검색을 하여 Create New Jypyter Notebook을 선택합니다.
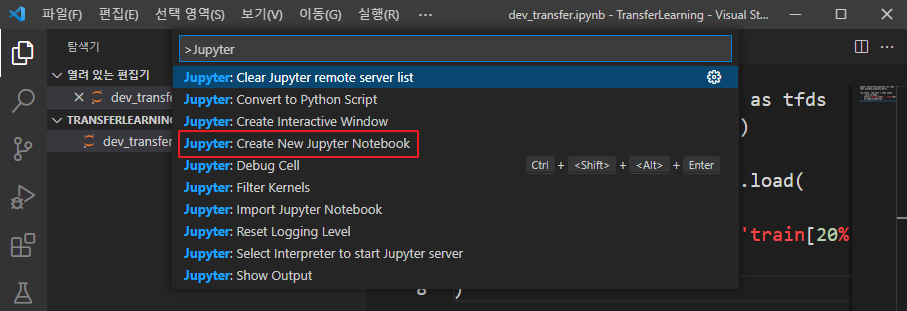
파일 이름은 dev_transfer.ipynb라는 파일명으로 입력합니다.
여기까지가 Visual Studio Code에서 Jupyter Notebook을 설치하는 과정입니다.
tensorflow_dataset 과 전이학습을 통하여 고양이 개 분류를 해보겠습니다. 텐서플로의 데이터셋 프로젝트인 TFDS 라이브러리를 설치하려면 커맨드 창에서 pip install tensorflow-datasets 으로 패키지를 설치하면 됩니다.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
raw_train, raw_test = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[20%:]'],
as_supervised=True
)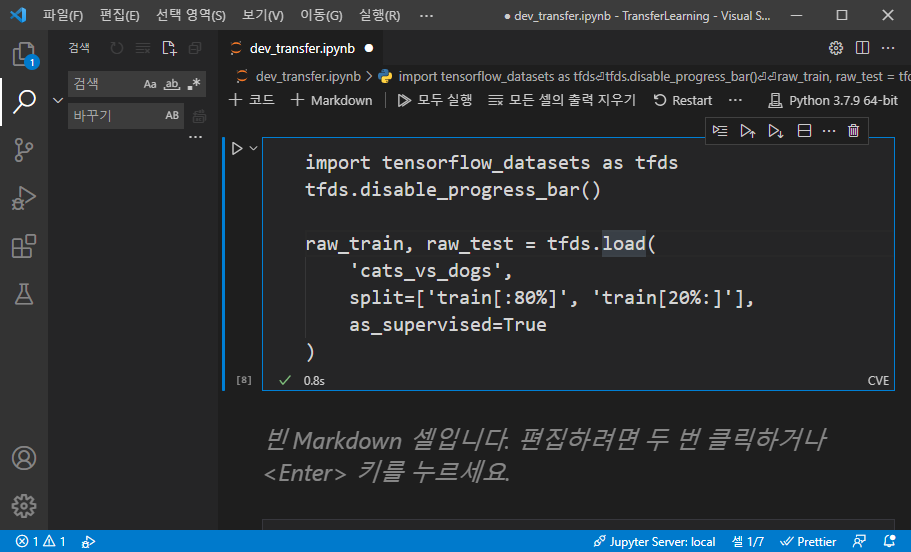
상기 코드에서 tfds.disable_progress_bar()함수를 호출하여 로그를 출력하지 않도록 설정합니다. 설정하지 않으면 데이터를 다운로드하는 과정에서 많은 로그가 출력됩니다.
tfds.load() 함수를 이용하여 데이터를 받고 raw_train, raw_test 변수에 데이터를 저장합니다. load() 함수의 첫 번째 인자로 데이터명을 전달하고, 두 번째 인자로 split 속성을 이용하여 데이터의 80%를 raw_train에, 20%를 raw_test에 할당합니다.
as_supervied 값은 데이터의 형태를 결정하는데 True로 설정하면 (input, label) 형태의 튜플 자료형을 반환하고 False를 설정하면 데이터별 고유한 dictionary 형태로 반환합니다.
import numpy as np
import tensorflow as tf
from tensorflow.image import ResizeMethod
def preprocess(image, label):
out_image = tf.image.resize(image, [224, 224], method=ResizeMethod.BICUBIC)
out_image = tf.keras.applications.mobilenet_v2.preprocess_input(out_image)
return out_image, label
batch_size = 32
train_batch = raw_train.map(preprocess).batch(batch_size)
test_batch = raw_test.map(preprocess).batch(batch_size)케라스 애플리케이션은 입력 이미지의 크기가 96, 128, 160, 192, 224인 MobileNet 모델만 지원하기 때문에 preprocess() 함수 안에서 바이큐빅 보간법을 이용하여 입력 이미지의 크기를 224 * 224 크기 변환합니다.
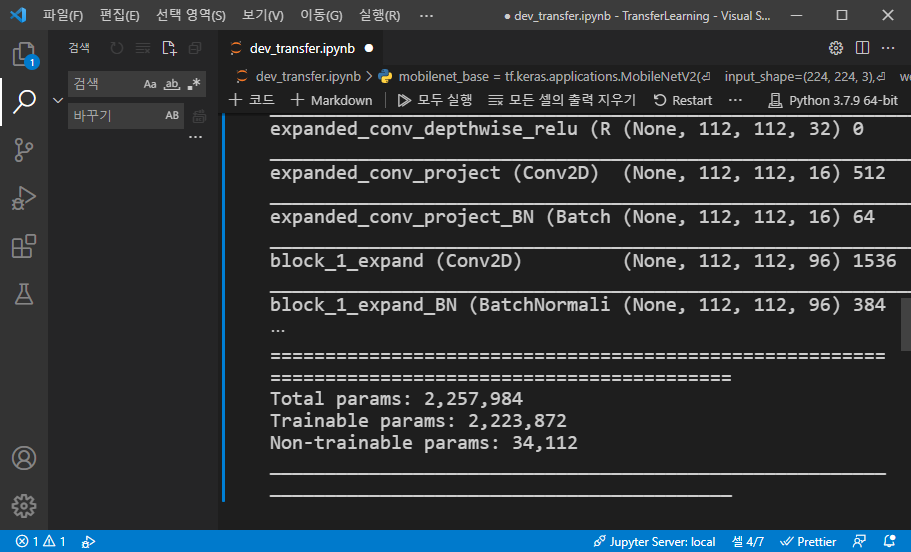
mobilenet_base = tf.keras.applications.MobileNetV2(
input_shape=(224, 224, 3),
weights="imagenet",
include_top=False)
mobilenet_base.summary()tf.keras.applications.MobileNetV2 클래스를 통해 모델을 생성하고 파라미터로 입력 데이터의 크기와 weights, include_top을 지정했습니다. weights는 "imagenet"으로 설정하여 ImageNet 데이터로 학습된 모델을 얻었습니다. include_top False로 설정하면 모델의 마지막 풀링 레이어와 Dense 레이어를 제외한 모델을 얻을 수 있습니다.
mobilenet_base.trainable=False
mobilenet_model = tf.keras.Sequential([
mobilenet_base,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(1)
])
mobilenet_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
mobilenet_model.fit(train_batch, epochs=5)먼저 tf.keras.Sequential() 함수를 이용하여 모델을 생성하는 코드를 살펴보겠습니다. 마지막 레이어를 제거한 MobileNet 모델인 mobilenet_base를 모델에 추가한 후, 제거된 레이어와 같은 역할을 해줄 풀링 레이어와 Dense 레이어를 추가했습니다. 모델의 목적은 개와 고양이 이미지를 구분하는 것이므로 Dense 레이어 노드가 1개면 충분합니다.
또한 이미 학습이 완료된 mobilenet_base의 가중치가 더 이상 학습되지 않도록 막기 위해 mobilenet_base.trainable 값을 False로 설정했습니다. 일반적으로 전이 학습은 이미 학습된 가중치가 더 이상 학습되지 않도록 동결시키고 훈련을 진행합니다. 나중에 성능 향상을 위해 모델을 다시 학습 가능하도록 되돌리고 학습률(Learning rate)를 낮추어 전체를 다시 한번 학습하며 미세 튜닝을 할 수 있습니다.
개와 고양이 이미지를 분류하는 문제는 이진 분류이므로 손글씨 분류와 달리 손실 함수도 binary_crossentropy로 바꿔야 합니다. 나머지 컴파일, 학습, 훈련 코드는 기존 모델과 동일합니다. 모델을 평가한 결과, 정확도 96.2%로 상당히 정확하게 분류할 수 있는 모델을 얻었습니다.
mobilenet_model.evaluate(test_batch, verbose=2)
728x90
반응형
'AI > 개발도구' 카테고리의 다른 글
| 포켓몬상 테스트 PWA 배포 도전기!! - 종료 (0) | 2022.07.25 |
|---|---|
| PIPREQS - 특정 프로젝트에 있는 파이썬 패키지만 requirements.txt 로 만들기 (0) | 2022.04.12 |
| ImportError libGL.so.1 cannot open shared object file No such file or directory STREAMLIT (0) | 2022.04.12 |
| 케라스(Keras), KeyError: 'acc' (0) | 2022.03.16 |
| 윈도우에서 MiniConda 및 Labelme 설치 하기 (0) | 2022.01.24 |





댓글 영역