고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
기본미션
코랩 실습 화면 캡처 하기.
도미 데이터 준비하기
#생선의 길이
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
#생선의 무게
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
import matplotlib.pyplot as plt #matplotlib의 pyplot 함수를 plt로 줄여서 사용
plt.scatter(bream_length, bream_weight)
plt.xlabel('length') # x축은 길이
plt.ylabel('weight') # y축은 무게
plt.show()
도미 35마리를 2차원 그래프에 점으로 나타냈습니다. x축은 길이, y축은 무게입니다. 2개의 특성을 사용해 그린 그래프이기 때문에 2차원 그래프라고 말합니다.
생선의 길이가 길수록 무게가 많이 나간다고 생각하면 이 그래프 모습은 매주 자연스럽습니다. 이렇게 산점도 그래프가 일직선에 가까운 형태로 나타나는 경우를 선형(linear)적이라고 말합니다. 머신러닝에서는 선형이라 단어가 종종 등장합니다.
빙어 데이터 준비하기
#빙어 데이터 준비하기
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()scatter 메소드에 smelt_length, smelt_weight를 추가하고 출력한다.

맷플롯립은 친절하게 2개의 산점도를 색깔로 구분해서 나타냅니다. 노란색 점이 빙어의 산점도입니다.
첫 번째 머신러닝 프로그램
k-최근접 이웃 알고리즘을 사용해 도미와 빙어 데이터를 구분하겠습니다. k-최근접 이웃 알고리즘을 사용하기 전에 앞에서 준비했던 도미와 빙어 데이터를 하나의 데이터로 합치겠습니다. 파이썬에서는 다음처럼 두 리스트를 더하면 하나의 리스트로 만들어 줍니다.
length = bream_length + smelt_length
weight = bream_weight + smelt_weightzip() 함수로 나열된 리스트 각각에서 하나씩 원소를 꺼내 반환하고 출력합니다.
fish_data = [[l, w] for l, w in zip(length, weight)]
print(fish_data)
머신러닝은 물론이고 컴퓨터 프로그램은 문자를 직접 이해하지 못합니다. 대신 도미와 빙어를 숫자 1과 0으로 표현해 보겠습니다. 예를 들어 첫 번째 생선은 도미이므로 1이고 마지막 생성은 빙어이므로 0이 됩니다.
앞서 도미와 빙어를 순서대로 나열했기 때문에 정답 리스트는 1이 35번 등장하고 0이 14번 등장하면 됩니다. 곱셉 연산자를 사용하면 파이썬 리스트를 간단하게 반복시킬 수 있습니다.
fish_target = [1] * 35 + [0] * 14
print(fish_target)
note 머신러닝에서는 2개를 구분하는 경우 찾으려는 대상을 1로 놓고 그 외에는 0으로 놓습니다. 위의 예는 도미를 찾는 대상으로 정의했기 때문에 도미를 1로 놓고 빙어를 0으로 놓았습니다. 반대로 빙어를 찾는 대상으로 놓고 빙어를 1로 놓아도 됩니다.
이제 사이킷런 패키지에서 k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborClassfier를 임포트 하여 훈련을 하고 출력하겠습니다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
kn.score(fish_data, fish_target)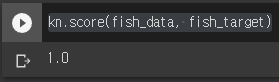
참고 데이터를 49개로 한 kn49 모델로 결과 확인 하기
# 참고 데이터를 49개로 한 kn 49 모델
kn49 = KNeighborsClassifier(n_neighbors=49)
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
가장 가까운 데이터를 49개를 사용하는 k-최근접 이웃 모델에 fish_data를 적용하면 fish_data에 있는 모든 생선을 사용하여 예측하게 됩니다. 다시 말하면 fish_data의 데이터 49개 중에 도미가 35개로 다수를 차지하므로 어떤 데이터를 넣어도 무조건 도미로 예측할 것이다. n_neighbors 매개변수를 49로 두는 것은 결과가 좋지 않다.
훈련 세트와 테스트 세트
zip 함수와 slice 를 이용하여 print 하는 코드 입니다.

슬라이싱 연산으로 인덱스 0~34까지 처음 35개 샘플을 훈련 세트로 선택, 인덱스 35~48까지 나머지 14개 샘플을 테스트 세트로 선택하고 모델을 훈련하고 평가해 보겠습니다.

score 의 값이 0 나온다. 이유는? train 데이터와 test 데이터를 확인해 보면 알 수 있다. 샘플링 편향이 생긴 문제이며 훈련세트와 테스트 세트를 나눌때 도미와 빙어 데이터가 골고루 섞이게 했어야 한다. 일반적으로 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향이라고 부릅니다.


numpy 를 사용하여 배열 내부를 무작위로 섞습니다.


파란색이 훈련 세트이고 주황색이 테스트 세트입니다. 양쪽에 도미와 빙어가 모두 섞여있는 것을 확인 할 수 있습니다.

선택 미션
Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기
1. 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습방법은 무엇인가요?
지도학습
2. 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
샘플링 편향
3. 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
행: 샘플, 열 : 특성
용어 정리
인공지능 artificial intelligence은 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술입니다. 인공지능은 강인공지능과 약인공지능으로 나눌 수 있습니다.
머신러닝은 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야입니다. 사이킷런이 대표적인 라이브러리입니다.
딥러닝은 인공 신경망이라고도 하며, 텐서플로와 파이토치가 대표적인 라이브러리입니다.
코랩은 구글 계정이 있으면 누구나 사용할 수 있는 웹 브라우저 기반의 파이썬 코드 실행 환경입니다.
노트북은 코랩의 프로그램 작성 단위이며 일반 프로그램 파일고 달리 대화식으로 프로그램을 만들 수 있기 때문에 데이터 분석이나 교육에 매우 적합합니다. 노트북에는 코드, 코드의 실행결과, 문서를 모두 저장하여 보관할 수 있습니다.
구글 드라이브는 구글이 제공하는 클라우드 파일 저장 서비스입니다. 코랩에서 만든 노트북은 자동으로 구글 클라우드의 'Colab Notebooks' 폴더에 저장되고 필요할 때 다시 코랩에서 열 수 있습니다.
이진 분류 머신러닝에서는 여러 개의 종류(혹은 클래스(class)라고 부릅니다) 중 하나를 구별해 내는 문제를 분류(classification)라고 부릅니다. 특히 이 장에서처럼 2개의 클래스 중 하나를 고르는 문제를 이진 분류(binary classification)라고 합니다. 여기에서 클래스는 파이썬 프로그램의 클래스와는 다릅니다. 혼동하지 마세요.
특성은 데이터를 표현하는 하나의 성질입니다. 이 절에서 생선 데이터 각각의 길이와 무게 특성으로 나타냈습니다.
머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정을 훈련이라고 합니다. 사이킷런에서는 fit() 메서드가 하는 역할입니다.
k-최근접 이웃 알고리즘은 가장 간단한 머신러닝 알고리즘 중 하나입니다. 사시 ㄹ어떤 규칙을 찾기보다는 전체 데이터를 메모리에 가지고 있는 것이 전부입니다.
머신러닝 프로그램에서는 알고리즘이 구현된 객체를 모델이라고 부릅니다. 종종 알고리즘 자체를 모델이라고 부르기도 합니다.
정확도는 정확한 답을 몇 개 맞혔는지를 백분율로 나타낸 값입니다. 사이킷런에서는 0~1 사이의 값으로 출력됩니다.
정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)
지도학습은 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용합니다. 1장에서부터 사용한 k-최근접 이웃이 지도 학습 알고리즘입니다.
비지도 학습은 타깃 데이터가 없습니다. 따라서 무엇을 예측하는 것이 아니라 입력 데이터에서 어떤 특징을 찾는 데 주로 활용합니다.
훈련 세트는 모델을 훈련할 때 사용하는 데이터입니다. 보통 훈련 세트가 클수록 좋습니다. 따라서 테스트 세트를 제외한 모든 데이터를 사용합니다.
테스트 세트는 전체 데이터에서 20~30%를 테스트 세트로 사용하는 경우가 많습니다. 전체 데이터가 아주 크다면 1%만 덜어내도 충분할 수 있습니다.
728x90
반응형
'Developer > 혼공단' 카테고리의 다른 글
| 혼공단 자바스크립트 6주차 미션 - Chapter 07 ~ 08 (0) | 2022.02.22 |
|---|---|
| 혼공단 자바스크립트 5주차 미션 - Chapter 06 (1) | 2022.02.13 |
| 혼공단 7기 일정 (0) | 2022.02.06 |
| 혼공단 자바스크립트 4주차 미션 - Chapter 05 (0) | 2022.02.02 |
| 혼공단 자바스크립트 3주차 미션 - Chapter 04 (0) | 2022.01.25 |





댓글 영역